Traditional depth sensors generate accurate real world depth estimates that surpass even the most advanced learning approaches trained only on simulation domains. Since ground truth depth is readily available in the simulation domain but quite difficult to obtain in the real domain, we propose a method that leverages the best of both worlds. In this paper we present a new framework, ActiveZero, which is a mixed domain learning solution for active stereovision systems that requires no real world depth annotation. First, we demonstrate the transferability of our method to out-of-distribution real data by using a mixed domain learning strategy. In the simulation domain, we use a combination of supervised disparity loss and self-supervised losses on a shape primitives dataset. By contrast, in the real domain, we only use self-supervised losses on a dataset that is out-of-distribution from either training simulation data or test real data. Second, our method introduces a novel self-supervised loss called temporal IR reprojection to increase the robustness and accuracy of our reprojections in hard-to-perceive regions. Finally, we show how the method can be trained end-to-end and that each module is important for attaining the end result. Extensive qualitative and quantitative evaluations on real data demonstrate state of the art results that can even beat a commercial depth sensor.
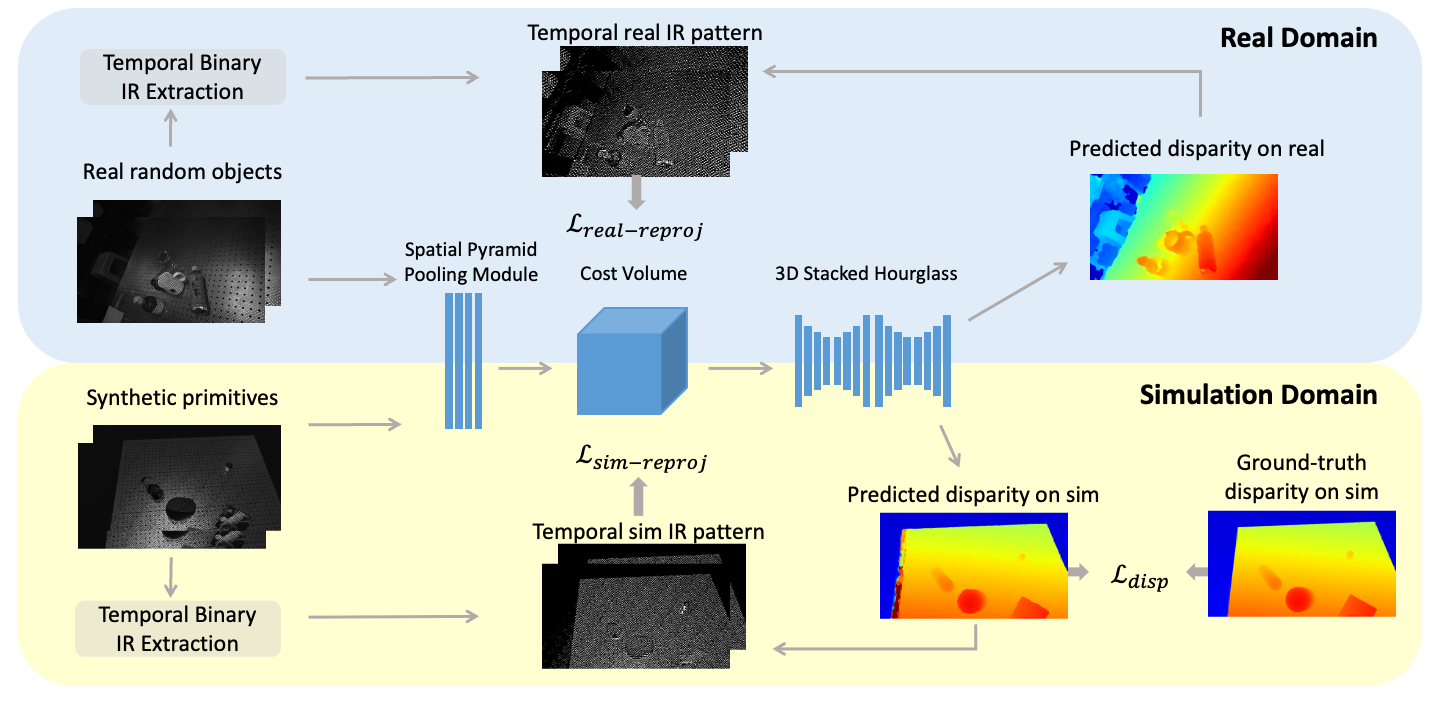
Figure 1. Architecture overview. The simulated and real stereo IR images are fed to a shared weight stereo network consisting of a CNN for noise reduction and a cost-volume-based 3D CNN for disparity prediction. The network is trained with reprojection loss on temporal binary IR pattern in the real domain, reprojection loss and disparity loss in the simulation domain as mixed domain learning. |
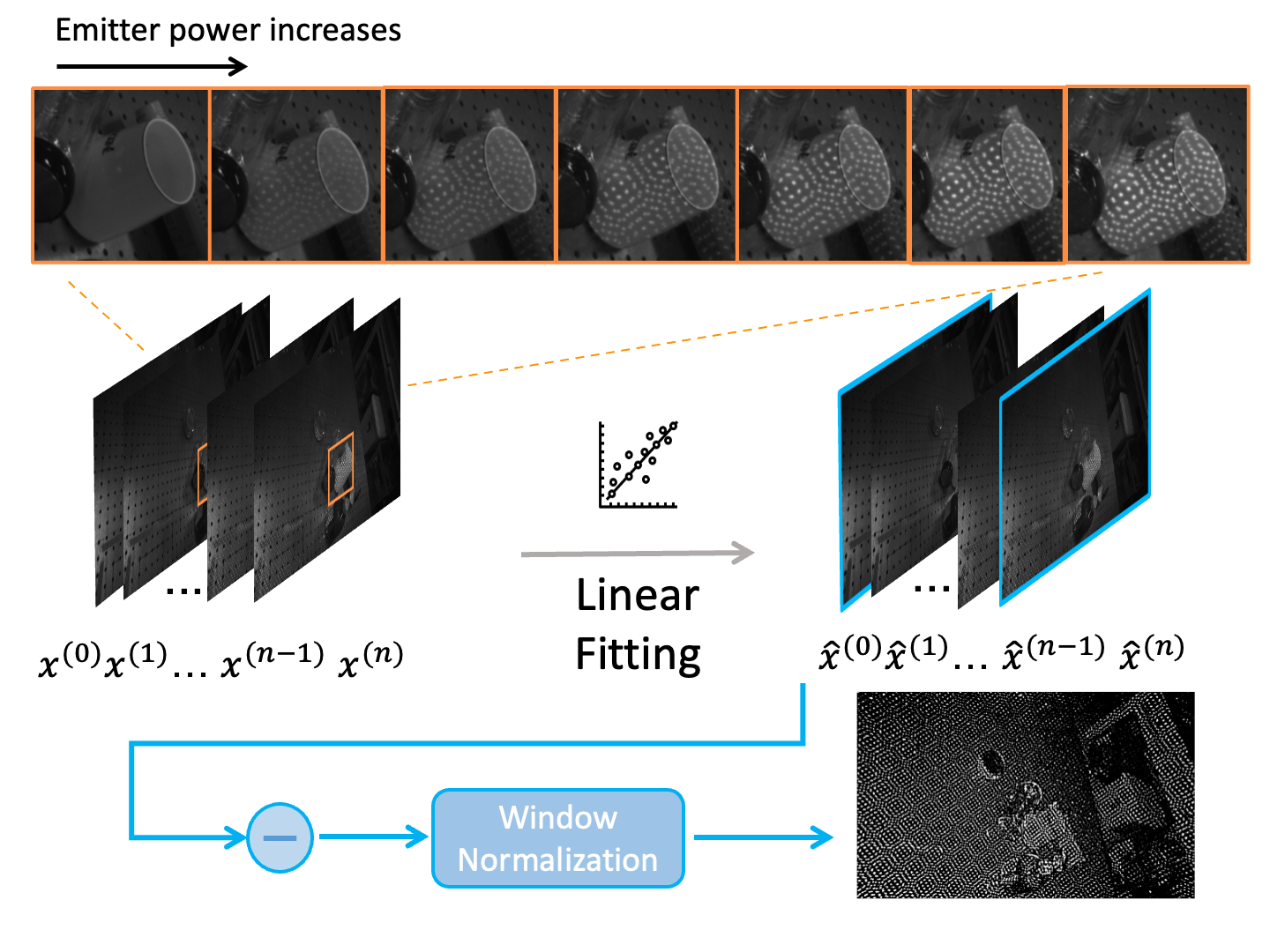
Figure 2. Temporal binary pattern extraction module. To eliminate the signal noise, we obtain a temporal sequence of IR images by gradually increasing the emitter power from the projector and do linear fitting on the sequence. The binary pattern is computed after window normalization. |
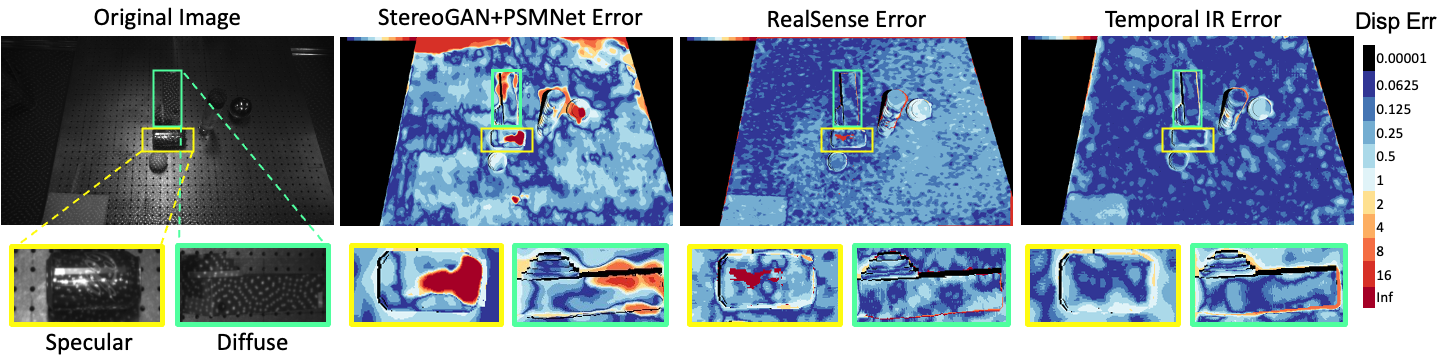
Figure 3. Comparison of the disparity error map of our method with StereoGAN and RealSense D415. Our method improves disparity accuracy on both 3D-printed diffuse objects and real specular objects. |
Figure 4. More qualitive result on predicted disparity error map. |

Figure 5. Comparison of extracted pattern and reprojection loss along the epipolar line. LCN pattern represents local contrast normalization which consists of continuous values; 2-step IR pattern and temporal IR pattern represent the extracted binarized pattern from temporal IR image sequence using n=1 and n=6, respectively. Temporal IR pattern with n=6 is optimal with a clear pattern and correct global minima on loss curve. |

Figure 6. Example images from our dataset. (a) the simulation training dataset of random shape primitives; (b) the real training dataset of random objects different from testing; (c) the sim2real aligned testing dataset, including specular surfaces such as metals and translucent bodies such as liquids. Note: we don't rely on any annotation for real scenes which is why we have no disparity annotation in (b). |